前回まで
OllamaをCPUで動作させたところ、めちゃくちゃ遅かったです。
前回の記事↓↓↓

Ollama(オラマ)試してみた!
はじめにチャッピーで調べて実行してみた。CPU動作でカテゴリ分類をしてもらう。軽快に動くとのこと。ゴール記事タイトル↓ローカルLLM↓カテゴリ分類をLinuxで動かす。環境構築私の環境では、VirtualBoxでやってみました。作業フォルダ…
km1ab.com
2026.05.08
改善できるところ
単にダメというのではなく、Ollamaの使い方や仮想マシンの設定も影響したようでした。
Ollamaの使い方と仮想マシンの設定変更を行ったところ、
結果が出るまでの時間を1分程度まで短くすることが出来ました。
モデル
モデルは、「qwen3:1.7b」を使うようにしました。
これによりモデルが軽くなるらしい。分類程度の処理で、4bは少々贅沢とのこと。
Bash
ollama pull qwen3:1.7bソース
- メソッドでgenerateを使うようにしました。 →その方が速いらしい
- また、keep_aliveを設定 →モデルのロードが速い?
Python
import ollama
prompt = """
以下カテゴリから最適なものを1つ選べ。
カテゴリ:
- Python
- Linux
- WordPress
- ComfyUI
- Stable Diffusion
記事タイトル:
ComfyUIでLoRAを使う方法
カテゴリだけ返せ。
"""
# response = ollama.chat(
response = ollama.generate(
# model="qwen3:4b",
model="qwen3:1.7b",
# options={"temperature": 0},
# messages=[{"role": "user", "content": prompt}],
prompt=prompt,
keep_alive='30m'
)
# print(response["message"]["content"])
print(response["response"])
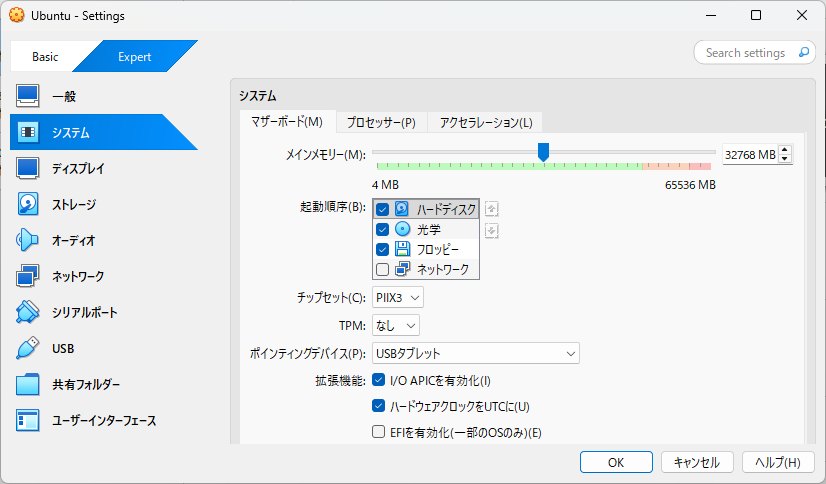
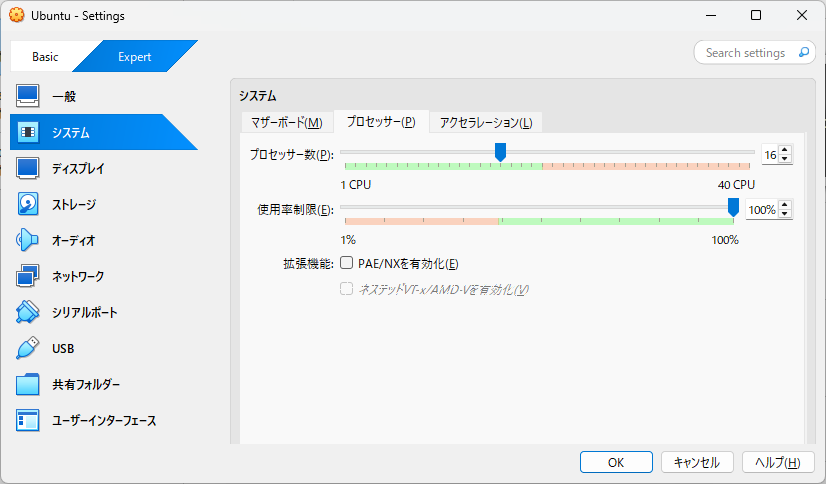
VirtualBOXの設定
キャプチャの通り、以下を割り当てました。
- メモリ:32GB ※前回は8GB
- CPU :16コア ※前回は8コア
実行
約1分になりました。前回の9分から大きな進歩です。
答えである「ComfyUI」も正解で、結果のブレもありません。
Bash
(venv) :~/llm_categolizer$ date && python3 test.py && date
2026年 5月 9日 土曜日 11:41:13 JST
ComfyUI
2026年 5月 9日 土曜日 11:42:14 JST
(venv) :~/llm_categolizer$ 講評
まぁいいんじゃないでしょうか。
1件当たり1分なので、記事が100件あったら100分ですね。
でも、放置して分類自動化を組めるのであれば、それもありかなと。
定期実行でカテゴライズさせるようにしても面白いかも。ブログの自動最適化ですかね。

コメント